
AI Data Center: The Importance of Power, Cooling, and Load Balancing
How are we equipping our data centers for artificial intelligence?
As artificial intelligence increasingly influences data center workloads, HorizonIQ is equipping our data centers to handle the unique challenges AI poses. From large training clusters to small edge inference servers, AI’s demand for higher rack power densities necessitates a novel data center design and management approach.
Our approach is grounded in understanding the distinct attributes and trends of AI workloads, which include the thermal design power (TDP) of GPUs, network latency, and AI cluster sizes.
AI workloads are typically classified into training and inference, each with its infrastructure demands. Training involves large-scale distributed processing across numerous GPUs, necessitating significant power and cooling resources. However, inference often requires a combination of accelerators and CPUs to manage real-time predictions—with varying hardware needs depending on the application.
Let’s go over what is required of data centers to support artificial intelligence and discuss the crucial role load balancers play in the allocation of AI workloads.

How are we upgrading power and cooling systems to support AI workloads?
To support high-density workloads, we’re enhancing our data center infrastructure across several key categories. For power management, we’re moving from traditional 120/208 V distribution to more efficient 240/415 V systems, allowing us to better handle the high power demands of AI clusters.
We’re also increasing the capacity of our power distribution units (PDUs) and remote power panels (RPPs) to support the larger power blocks required by AI applications. This includes deploying custom rack PDUs capable of handling higher currents to provide reliable power delivery to densely packed racks.
Cooling infrastructure is also being upgraded to manage the increased thermal output of high-performance GPUs. Our cooling strategies are designed to maintain optimal operating temperatures. This prevents overheating and ensures the longevity and reliability of our equipment.
We’re also implementing advanced software management solutions and new load balancers to monitor and optimize power and cooling efficiency in real time—further enhancing our ability to support AI workloads.
What makes load balancing essential to AI data centers?
Think of load balancing as a traffic control for data centers. Just as traffic lights manage cars at intersections to prevent traffic jams, load balancing makes sure that the data flows smoothly in data centers. It’s crucial for maintaining high performance and preventing network congestion.
With AI data centers, efficient load balancing becomes even more vital due to the massive amounts of data being processed.
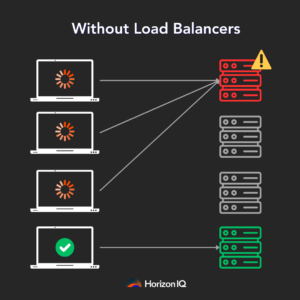
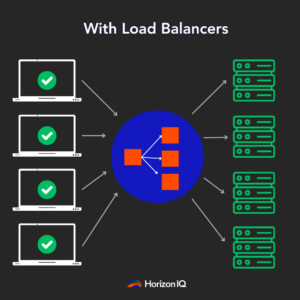
Why has load balancing become a hot topic in AI data centers?
Let’s consider the analogy of a busy highway. Imagine a highway filled with semi trucks (elephant flows) and small cars (normal data).
In AI data centers, the “trucks” carry large data loads between GPU clusters during the training phase. If these trucks aren’t managed properly, they can clog the highway and jam traffic. This is similar to data congestion in a network, which can slow down data processing and impact the performance of AI models.
As stated earlier, AI workloads typically involve two phases: training and inference. During training, data is shuffled between GPUs to optimize the model. This process generates large data flows, or elephant flows.
These flows need to be balanced across the network to avoid congestion and inefficient data transfer. Therefore, efficient load balancing is crucial to managing these heavy data loads and maintaining high AI infrastructure performance.
How do AI data centers handle load balancing?
AI data centers use GPU clusters to train models. Think of these clusters as teams working together on a project. They’re constantly sharing information (memory chunks) to improve performance. This data sharing needs to be fast and seamless.
For instance, in an NVIDIA server, memory chunks are communicated within the server using NVIDIA Collective Communication Libraries (NCCL). If data needs to move from one server to another, it uses Remote Direct Memory Access (RDMA) traffic.
RDMA traffic is critical because it moves the data directly between memory locations, minimizing latency and maximizing speed. Efficient load balancing of RDMA traffic is essential to avoid bottlenecks and ensure smooth data transfer.
What are the current methods for load balancing?
There are two main load balancing methods used in AI data centers:
- Static Load Balancing (SLB): SLB assigns data flow to the path less traveled. While SLB is effective for smaller data flows, it doesn’t adapt well to changing traffic conditions or large data loads. SLB uses a hash-based mechanism where the switch looks into the packet header, creates a hash, and checks the flow table to determine the outgoing interface.
- Dynamic Load Balancing (DLB): This method monitors traffic and adjusts paths based on current conditions. It’s like a smart GPS that reroutes you based on real-time traffic data. DLB uses algorithms to consider link utilization and queue depth and assigns quality bands to each outgoing interface. This ensures that data flows are dynamically balanced to improve efficiency. DLB is particularly effective for handling heavy data loads in AI.
What are the challenges with load balancing?
Efficient load balancing in AI data centers is complex due to several challenges:
- Elephant Flows: Large data transfers between GPU clusters are difficult to manage. If not balanced properly, they can cause congestion, leading to packet loss and delays.
- Entropy: Low entropy in data flows makes it hard to differentiate packets. High entropy allows better segregation and load balancing of traffic, while low entropy makes it challenging to distribute the load evenly across the network.
- Congestion Control: Without proper load balancing, data centers can experience congestion, leading to packet drops and increased job completion times. Effective load balancing ensures a lossless fabric to minimize delays and maintain high performance.
- Reordering: When packets are distributed across multiple paths, they can arrive out of order. This reordering needs to be handled carefully to avoid disrupting data flows. Advanced network interface cards (NICs) and protocols help efficiently manage packet reordering.
How HorizonIQ can support your next AI project
As AI transforms data center operations, HorizonIQ is proud to enhance our infrastructure with groundbreaking solutions. Our upgraded data centers now feature the latest NVIDIA GPUs and advanced load balancers—designed to meet the demanding needs of AI and high-performance computing.
HorizonIQ’s NVIDIA GPU lineup:
- NVIDIA A16: Ideal for virtual desktop infrastructure (VDI) and video tasks. It’s perfect for office productivity and streaming—starting at $240/month.
- NVIDIA A100: Need extraordinary acceleration? With 80GB of memory and 2TB/s bandwidth, it’s designed for extensive model training and complex simulations—starting at $640/month.
- NVIDIA L40S: Looking for breakthrough performance in AI and graphics? The L40S combines top-tier AI compute with premium graphics and media acceleration—starting at $1,000/month.
Our advanced load balancers:
- Virtual Load Balancer: Our cost-effective solution features dynamic load balancing, SSL termination, and handles up to 500k L4 connections per second.
- Dedicated Load Balancer: Get up to 1MM L4 connections per second, dedicated hardware, and full SSL termination. Ideal for web hosting and eCommerce.
- Advanced Dedicated Load Balancer: Our top-tier option for high-performance computing needs. With up to 5MM L4 connections per second and 80Gbps throughput, it includes advanced features like traffic steering and caching to enhance the performance of your AI applications.



