Month: February 2025

RAG vs Fine Tuning: Choosing the Best Approach for AI Optimization
As artificial intelligence continues to advance at a rapid pace, businesses and developers are looking for ways to refine and enhance Large Language Models (LLMs) for specialized applications. Two of the most effective techniques for this are Retrieval-Augmented Generation (RAG) and fine tuning. While both approaches improve model accuracy and relevance, they achieve this in distinct ways. Understanding RAG vs fine tuning strengths, weaknesses, and ideal use cases is essential for choosing the right method for your AI deployment.
Let’s explore when to choose one over the other—or how combining both can create the most effective AI solutions for AI-powered search tools, industry-specific chatbots, adaptive automation, and more.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) enhances LLMs by allowing them to pull in external, real-time information to supplement their responses.
Instead of relying solely on the data they were trained on, RAG-equipped models can access documents, structured databases, and APIs to generate more precise and relevant answers.
How RAG Works:
- User Input: A query is submitted to the model.
- Retrieval Mechanism: The model searches a relevant knowledge base or database for contextual information.
- Augmentation Process: The retrieved data is incorporated into the model’s prompt.
- Response Generation: The model processes both the original prompt and the external data to produce an informed response.
Key Benefits of RAG:
- Access to Current Information – Keeps AI outputs up to date without retraining the model.
- Reduces Misinformation – Provides factual responses by referencing trusted sources.
- Adaptability – Allows models to function in dynamic environments with frequently changing information.
Common Use Cases for RAG:
- AI-powered search engines that need up-to-the-minute information.
- Enterprise knowledge bases that require retrieval of proprietary documents.
- Conversational AI assistants that provide accurate responses to users in real-time.
What is Fine Tuning?
Fine tuning takes a different approach by modifying an LLM’s internal parameters through additional training on a specialized dataset. This method is effective for tailoring a model’s responses to a specific domain, improving response style, and refining output consistency.
How Fine Tuning Works:
- Select a Pre-Trained Model: A general-purpose LLM serves as the foundation.
- Provide Specialized Training Data: A curated dataset containing domain-specific examples is used.
- Adjust Model Weights: The model is trained on this new data to optimize for specialized use cases.
- Deploy the Updated Model: The fine tuned version is now tailored for its specific task.
Key Benefits of Fine Tuning:
- Customization for Industry-Specific Needs – Enhances models to understand legal, medical, or financial terminology.
- Improved Response Accuracy – Reduces the chance of incorrect or generic responses by embedding knowledge directly into the model.
- Efficiency Gains – Optimized responses reduce processing time and computational costs.
Common Use Cases for Fine Tuning:
- Legal or financial document summarization with precise terminology.
- Customer support chatbots that align with brand voice and policies.
- Healthcare AI assistants trained on medical research and guidelines.
Comparing RAG and Fine Tuning
| Feature | RAG | Fine Tuning |
| Primary Benefit | Enhances responses with real-time external data | Embeds specialized knowledge into the model |
| Training Required? | No | Yes (requires domain-specific dataset) |
| Model Updates? | Fetches latest info dynamically | Static, requires retraining for new knowledge |
| Best For | Keeping up with frequently changing information | Domain expertise and consistency |
When to Use RAG vs Fine Tuning?
RAG is Best For:
- Your AI application requires real-time, external knowledge retrieval (e.g., financial news updates, legal precedents).
- Accuracy and fact-checking are critical, and responses need to be sourced from verifiable documents.
- The AI model needs to remain flexible without frequent retraining.
Fine Tuning is Best For:
- Your model must operate in a highly specialized field (e.g., medicine, law, engineering).
- You require consistent tone, structure, and terminology that reflects your brand or industry.
- You need to optimize response speed and reduce token usage for cost efficiency.
Use Both RAG and Fine Tuning When:
- You need a domain-specific model that also requires access to real-time data.
- Your AI application demands both precision and adaptability (e.g., AI-powered financial advisors, research tools).
- You want to maximize accuracy while ensuring your model remains contextually relevant over time.
Rag vs Fine Tuning: Key Takeaways
Both RAG and fine tuning offer unique benefits for optimizing AI models. RAG provides real-time access to information, so that responses stay relevant and accurate, while fine-tuning refines model behavior and expertise for specialized applications.
In many cases, combining the approaches delivers the best of both worlds—allowing businesses to build AI solutions that are both intelligent and adaptable.
RAG Deployment on Private Cloud
HorizonIQ’s managed private cloud provides the ideal infrastructure for deploying AI models optimized with RAG, fine-tuning, or both. With dedicated resources, enhanced security, and scalable storage, our private cloud provides easy data retrieval for RAG-based models while offering the computational power needed for fine-tuning.
Whether you’re building real-time AI assistants, domain-specific automation, or hybrid intelligence solutions, HorizonIQ delivers the performance, flexibility, and control required to maximize AI efficiency.
Ready to optimize your AI in a secure, high-performance environment? Contact us today to help you build the foundation for smarter, more reliable AI applications.
Explore HorizonIQ
Bare Metal
LEARN MORE
Stay Connected



About Author


Want to build a chatbot that knows what it’s talking about? Most chatbots rely solely on pre-trained data, which means they often give vague or outdated responses.
That’s where RAG chatbots come in. A RAG enhances chatbot accuracy by dynamically fetching relevant information in real-time so that responses are both contextually appropriate and up-to-date.
In this article, you’ll explore RAG chatbots, how they work, and why RAG’s being used to build more intelligent chatbots. You’ll also discover the benefits of using RAG in private cloud environments and learn practical scenarios where RAG chatbots excel.
What are RAG Chatbots?
Retrieval-Augmented Generation (RAG) chatbots optimize the output of Large Language Models (LLMs) by integrating external authoritative knowledge sources before generating a response.
Unlike traditional chatbots that rely solely on pre-trained data, RAG chatbots dynamically retrieve relevant information from external databases, APIs, or document repositories. This technique enhances chatbot responses’ accuracy, relevance, and credibility—while reducing the need for expensive retraining.
Why are RAG Chatbots Becoming Popular?
RAG chatbots form a crucial part of artificial intelligence (AI) applications by improving user interactions. Whereas traditional LLMs used in chatbots have several limitations:
- Hallucinations: Traditional chatbots can generate false information when lacking knowledge of a specific topic.
- Static Knowledge: They often have a training data cut-off, rendering them unaware of recent developments or information.
- Non-authoritative Sources: Responses may be based on outdated or non-credible training data.
- Terminology Confusion: Similar terms used in different contexts can lead to misleading or irrelevant responses.
RAG chatbots mitigate these challenges by retrieving up-to-date and authoritative information before generating responses. This approach allows organizations to maintain control over AI-generated content by allowing to users receive fact-based, reliable information.
Implementing RAG technology in chatbots offers several advantages for organizations:
- Cost-Effective Implementation: Instead of retraining foundational models, RAG chatbots introduce new data dynamically, reducing computational and financial costs.
- Up-to-Date Information: RAG chatbots can reference the latest research, news, or internal documentation.
- Enhanced User Trust: By including citations and references in their outputs, RAG chatbots improve transparency and credibility with users.
- Greater Developer Control: Organizations can regulate the information sources that RAG chatbots access, restrict sensitive data, and refine AI-generated responses to meet specific business needs.
Pro tip: While RAG can be cost-effective, there are costs associated with maintaining and updating the external data sources and the infrastructure for real-time retrieval. These costs can sometimes be substantial—especially if the data sources are extensive or if compliance with data governance requires significant investment.
How Do RAG Chatbots Work?
RAG chatbots introduce an information retrieval component that supplements an LLM’s existing knowledge. The process involves four key steps:
- Creating External Data:
- External data sources include APIs, document repositories, and databases.
- Data is converted into vector representations and stored in a vector database.
- Retrieving Relevant Information:
- The user’s query is converted into a vector representation.
- A relevancy search is conducted against the vector database to find the most pertinent data.
- Example: Nanyang Technological University in Singapore deployed “Professor Leodar,” a custom-built, Singlish-speaking RAG chatbot designed to enhance student learning and reduce the dissemination of low-quality information.
- Augmenting the LLM Prompt:
- Retrieved data is combined with the user query to provide additional context.
- Prompt engineering techniques ensure that the LLM interprets the retrieved information effectively.
- Updating External Data:
- To maintain accuracy, external data repositories require continuous updates.
- This can be achieved through automated real-time processes or periodic batch updates.
Why Are Companies Choosing to Deploy RAG on Private Clouds?
Companies are increasingly opting for private or hybrid cloud deployments of RAG for several reasons:
- Data Sovereignty: Organizations are often required to comply with regulations that mandate the storage and processing of data within specific geographical boundaries. Private clouds offer the flexibility to meet these compliance requirements while maintaining control over sensitive information.
- Scalability and Performance: Private clouds can be tailored to the specific needs of an organization, allowing for optimized resource allocation. This customization leads to better performance and scalability compared to public cloud options.
- Enhanced Collaboration: With private cloud environments, teams can collaborate more effectively by leveraging shared resources and data—without the constraints often imposed by public cloud services.
What are the Benefits of RAG in a Private Cloud?
- Improved Security: Sensitive information remains more secure since all data processing happens within your controlled environment.
- Compliance with Regulations: Private cloud deployment provides better compliance with industry standards like HIPAA and GDPR.
- Reduced Latency: Processing queries within an internal network reduces response time compared to cloud-based APIs.
- Full Customization: You can train custom embedding models and optimize retrieval pipelines to match your domain-specific knowledge.

Optimizing RAG Performance in Private Cloud Environments
To enhance RAG chatbot performance, consider:
- Fine-tuning embeddings: Use domain-specific embedding models instead of generic ones.
- Caching frequent queries: Store commonly asked questions in memory for faster responses.
- Parallelizing retrieval: Optimize database queries for parallel execution to reduce retrieval time.
- Load balancing: Distribute chatbot requests across multiple servers to handle higher traffic.
Deploying a Rag Chatbot
Building a RAG chatbot and deploying it in a private cloud provides secure, accurate, and real-time responses. By following the steps outlined above, you can create a chatbot that dynamically fetches relevant data—while maintaining control over security and infrastructure.
HorizonIQ can provide you with the underlying hardware to deploy a RAG chatbot on our private cloud environments. With our infrastructure solutions, you will be able to self-manage a chatbot with the following features:
- Storage Redundancy: Leveraging technologies like ZFS to ensure high availability and data integrity.
- Resource Efficiency: Configuring hardware to maximize performance while minimizing costs.
- Security Enhancements: Setting up encrypted backups, secure access protocols, and TLS 1.3 for client-server communication.
Ready to get started? Contact us today to deploy your RAG chatbot on our private cloud environment.
Explore HorizonIQ
Bare Metal
LEARN MORE
Stay Connected
About Author

The AI industry is advancing at breakneck speed, and DeepSeek has recently made waves—and crashed stock markets—by claiming it trained a powerful AI model for just $5.6 million.
This is a fraction of what it costs to develop similar AI models in the U.S., which can range from $100 million to $1 billion. This raises an important question: Will DeepSeek change the way AI models are trained and, in turn, transform the data center industry?
What is DeepSeek?
DeepSeek is a Chinese AI company specializing in open-source large language models (LLMs). Its flagship model, DeepSeek-V3, powers an AI assistant that has gained significant traction, surpassing OpenAI’s ChatGPT in popularity.
A key differentiator of DeepSeek’s technology is its cost efficiency. While major AI firms like Meta train models on supercomputers with over 16,000 GPUs, DeepSeek-V3 was supposedly trained using only 2,000 Nvidia H800 GPUs. At what was claimed to be over 55 days at a fraction of the cost.
Despite this leaner infrastructure, its performance is competitive with leading AI models, excelling in answering complex queries, logic problems, and programming tasks. DeepSeek’s rapid rise has sparked global interest—with some viewing it as a challenge to U.S. AI dominance.
It has also faced scrutiny, with OpenAI investigating whether DeepSeek trained its model using proprietary ChatGPT data. Additionally, several countries, including Australia, Italy, Taiwan, and the U.S., have restricted DeepSeek’s use in government sectors due to security concerns.
Despite these challenges, DeepSeek’s ability to develop high-performing AI at a lower cost has positioned it as a disruptive force.
Is DeepSeek’s Cost Factor A Game Changer?
Training AI models requires massive computational resources, which has led many companies to need thousands of GPUs running in high-performance data centers.
The industry norm has been to pour billions into AI infrastructure, with companies like OpenAI, Google, and Meta investing heavily in specialized data centers to support their AI ambitions.
DeepSeek’s claim that it trained a cutting-edge model at a fraction of the cost challenges this assumption.
If true, it suggests that AI models might not need the same scale of hardware investment as previously thought. This could impact:
- The demand for high-performance GPUs
- The need for expansive data center facilities
- The electricity consumption required to train AI
Companies spending billions on AI infrastructure might reassess their investments if AI training becomes significantly cheaper and more efficient.
The fact that AWS, Azure, and others have already released Deepseek into their cloud platforms demonstrates a significant shift in the industry towards more cost-effective and scalable solutions.
What Is DeepSeek’s Impact on Data Center Growth?
AI-driven data center expansion has been one of the biggest trends in tech. Nvidia, the leader in AI chips, has seen skyrocketing demand as companies race to build AI infrastructure.
The belief has been that more AI equals more data centers, more power consumption, and more hardware.
DeepSeek’s approach could challenge this logic in two ways:
- Less Need for Massive Compute: If AI models can be trained with fewer GPUs and at a lower cost, companies may not need to scale up their data centers at the same pace. This could slow down new data center construction projects.
- Shift Toward Smaller AI-Focused Data Centers: If AI models become more efficient, we may see a rise in smaller, more localized AI processing hubs instead of massive, centralized data centers.
However, there’s another possibility: If DeepSeek’s model makes AI training more accessible, more companies might enter the AI space, increasing the overall demand for data centers.
Is DeepSeek’s AI and Energy Consumption a Turning Point?
Training large AI models consumes enormous amounts of electricity, which is why power companies and data center operators have been preparing for a surge in energy demand.
If DeepSeek’s model truly operates with significantly lower power requirements, this could ease some of the concerns surrounding AI’s impact on global energy grids.
This could have multiple effects:
- Lower costs for AI startups: If AI models don’t require extreme power consumption, it could reduce entry barriers for smaller companies.
- Less reliance on hyperscale data centers: More efficient models could lead to a preference for distributed, modular data centers instead of massive hyperscale facilities.
- Shift in energy infrastructure investments: Power companies anticipating higher AI-related energy demand might need to reconsider their projections.
But there’s a catch: If AI adoption accelerates due to lower costs, overall energy consumption could still rise, even if individual models become more efficient.
What Is The Skepticism Around DeepSeek?
While DeepSeek’s claims are impressive, some industry experts, including Elon Musk, are skeptical. One major concern is whether DeepSeek had access to more GPUs than it is letting on. If DeepSeek secretly used significantly more compute resources, then its cost claims may not be entirely accurate.
Another concern is transparency. AI models trained in China often face scrutiny due to privacy, data security concerns, and censorship. Ask DeepSeek chat anything that may be viewed as controversial about China, and you’re bound to get this response:

Also, the reported $5.6 million cost does not necessarily include all prior research, data acquisition, or other hidden expenses. If these costs were excluded, the real expense of training DeepSeek’s model could be much higher.
What Does This Means for the Future of AI and Data Centers?
DeepSeek’s breakthrough raises more questions than answers. If its model truly represents a new, cost-effective way to train AI, it could disrupt the industry by:
- Reducing the need for hyperscale AI data centers
- Making AI more accessible to smaller companies
- Lowering energy consumption for AI processing
- Shifting investment strategies in AI infrastructure
However, if its claims turn out to be overstated, the AI industry may continue on its current path—one of increasing GPU demand, larger data centers, and skyrocketing energy consumption.
One thing is certain: The AI landscape is evolving rapidly. Whether DeepSeek is a disruptor or just another hype, its emergence signals that the industry is moving toward more efficiency and cost-conscious AI development.
The future of AI and data centers will depend on how these advancements play out in real-world applications.
Explore HorizonIQ
Bare Metal
LEARN MORE
Stay Connected


About Author
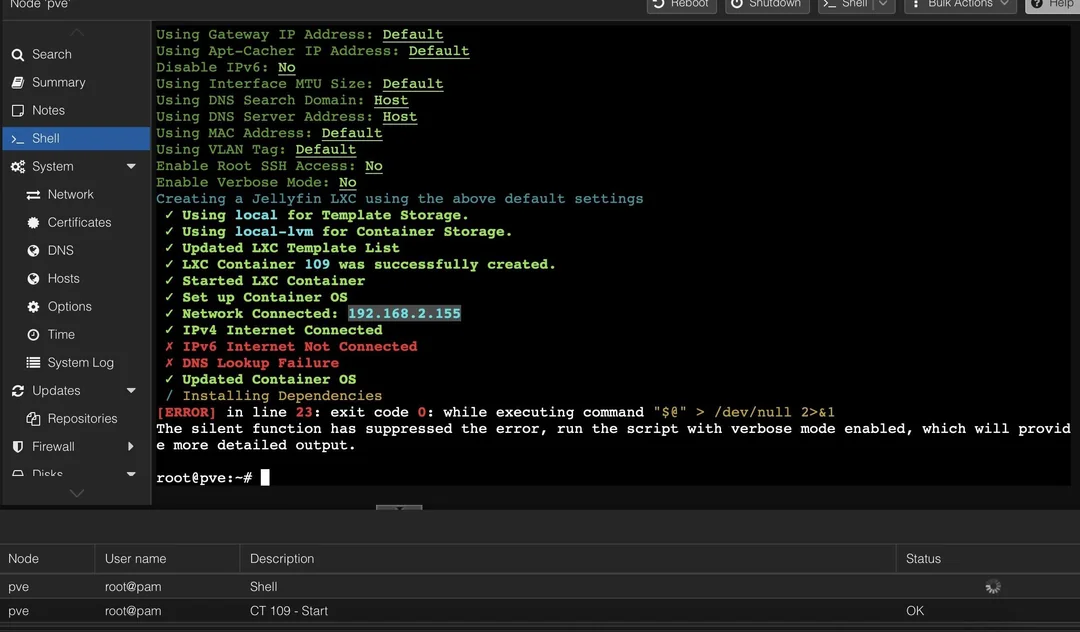
Proxmox VE is already an incredibly versatile open-source platform for virtualization. But what if you could streamline and automate many of its common tasks?
That’s where Proxmox Helper Scripts come in. They are a collection of open-source scripts designed to simplify and enhance your Proxmox experience. Let’s dive into these scripts’ technical aspects, demonstrating their power and how they can easily automate your Proxmox management workflow.
What Are Proxmox Helper Scripts?
Proxmox Helper Scripts are an open-source project aimed at automating and optimizing routine tasks in Proxmox VE. These scripts:
- Configure Proxmox VE repositories.
- Remove subscription nag screens.
- Clean up old kernels.
- Simplify the setup and management of LXC containers.
- Offer utilities for spinning up applications, maintaining LXC containers, backing up your Proxmox host configuration, and more.
What Are LXC Containers?
Before diving into the scripts, let’s understand the role of LXC containers, which are lightweight alternatives to virtual machines (VMs). Unlike VMs that include an isolated kernel, LXC containers share the host’s kernel.
They provide OS-level virtualization and are ideal for lightweight application hosting. While Docker focuses on application-level virtualization, LXC containers are better suited for full OS-like environments. Here’s a quick comparison:
| Aspect | LXC Containers | Docker Containers |
| Use Case | Hosting full OS environments with specific configurations. | Running isolated applications with pre-packaged dependencies. |
| Kernel Sharing | Shares the host’s kernel. | Shares the host’s kernel, but with stricter isolation. |
| Dependency Management | You install and manage dependencies manually. | Dependencies are bundled within the container image. |
| Update Risks | Updates to the OS or dependencies can break compatibility. | Updates to the host or app image rarely cause conflicts as images are self-contained. |
| Complexity | Offers flexibility but requires careful dependency management. | Simpler management with pre-built container images. |
What Are the Advantages of Working with LXC Containers?
One of the standout features of Proxmox Helper Scripts is its extensive support for LXC container management. The scripts simplify:
Application Deployment:
- Spin up lightweight LXC containers pre-configured with applications like databases, MQTT, ZigBee, and more.
- Examples include:
- Home Assistant installations (Core LXC or full HAOS as a VM).
Maintenance:
- Scripts to update containers.
- Automate backups of container configurations and data.
Efficiency:
With LXC containers, you reduce resource overhead compared to VMs while maintaining a secure and isolated environment for your applications.
Proxmox Helper Scripts: The Proxmox Post Install Script
A fresh Proxmox installation often requires some post-installation tweaks. The Proxmox Post Install Script automates these adjustments:
Features:
- Repository Management:
- Disables the enterprise repository (if no subscription is used).
- Enables the no-subscription repository.
- Optionally adds a test repository (disabled by default).
- Nag Screen Removal:
- Disables the subscription warning on login.
- High Availability Optimization:
- Disables high availability features on single-node setups to free up resources.
- System Updates:
- Updates Proxmox VE and ensures the latest kernel is installed.
- Reboot Prompt:
- Reboots the system to apply updates and kernel changes.
How to Execute:
- Review the Proxmox Post Install script.
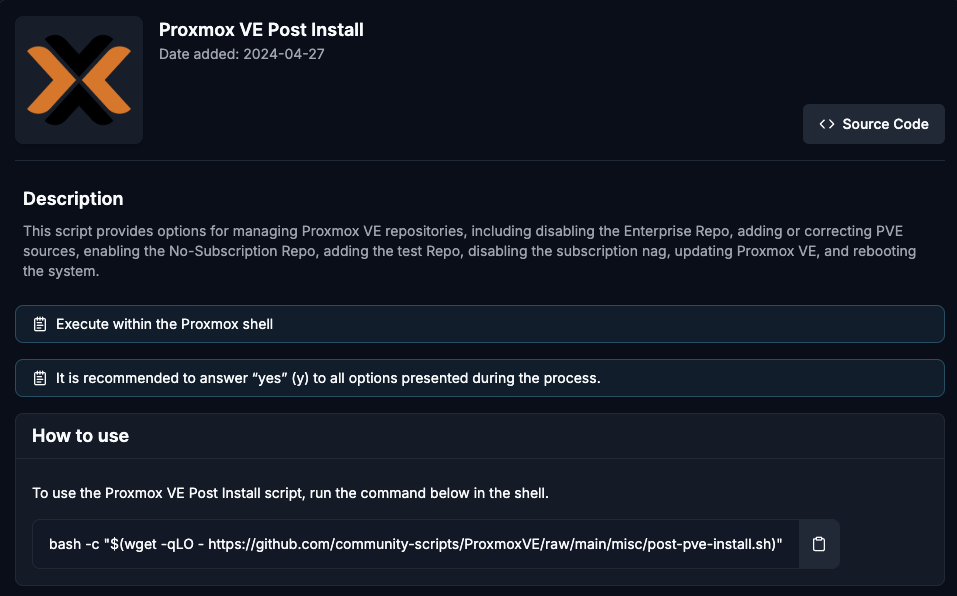
- To use the Proxmox Backup Server Post Install script, run the command below in the shell.
bash -c "$(wget -qLO - https://github.com/community-scripts/ProxmoxVE/raw/main/misc/post-pbs-install.sh)"
Proxmox Helper Scripts: Kernel Cleanup Script
As you update Proxmox over time, old kernels accumulate and consume valuable disk space. The Kernel Cleanup Script simplifies the removal of outdated kernels.
Steps:
- Review the Kernel Cleanup Script
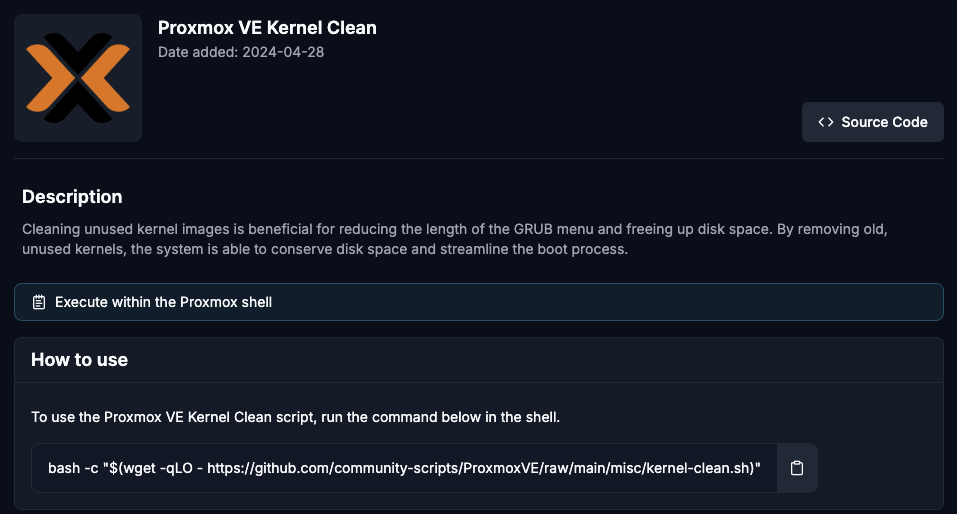
- Check your current kernel version:
uname -r - Run the Kernel Cleanup Script:
bash -c "$(wget -qLO - https://github.com/community-scripts/ProxmoxVE/raw/main/misc/kernel-clean.sh)" - Safeguards:
- The script does not delete the currently active kernel.
- It’s recommended to retain the last one or two kernels for fallback purposes.
Proxmox Helper Scripts: Proxmox Host Backup Script
Regular backups of your Proxmox configuration are crucial for disaster recovery. The Proxmox Host Backup Script automates the backup process so that your configurations are safe.
Features:
- Backs up the Proxmox VE configuration files.
- Stores the backup in a user-specified location.
- Can be scheduled for regular execution via cron.
How to Execute:
- Review the Proxmox VE Host Backup script:
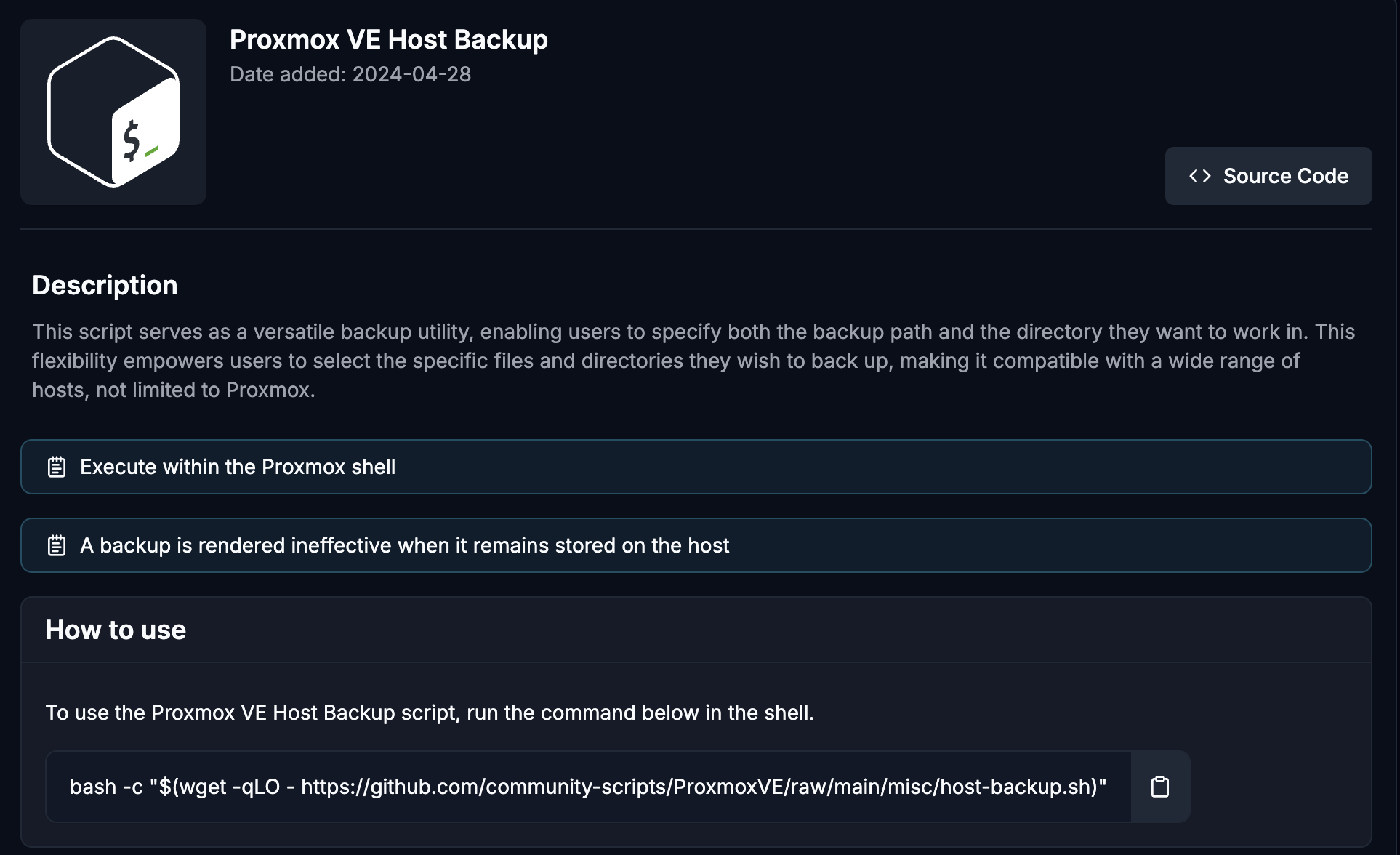
- Run the Script:
- Open the Proxmox shell and paste the backup script command.
bash -c "$(wget -qLO - https://github.com/community-scripts/ProxmoxVE/raw/main/misc/kernel-clean.sh)"
-
- The script will prompt you for configuration details.
- Choose Backup Destination:
- Select where you want to back up your files.
- Recommended: Mount a network directory (e.g., NFS or SMB share) and back up there.
- Alternative: Use a local directory for testing (e.g., /root/backups).
- Select where you want to back up your files.
- Select Files to Back Up:
- Specify the directory to back up:
- Recommended: /etc/pve (contains essential configurations for VMs, networks, etc.).
- Optionally, back up the entire /etc folder for a broader backup.
- Specify the directory to back up:
- Run the Backup:
- Confirm the source and destination paths.
- Let the script run and create a backup archive.
- Verify the Backup:
- Navigate to the backup destination (e.g., /root or the mounted network share).
- Check for the backup archive file (e.g., a .tar.gz file).
- Optional: Automate the Process
- Mount a network share permanently.
- Add the backup script to a cron job for regular execution.
What Are the Best Practices for Using Proxmox Helper Scripts?
- Review Scripts Before Execution:
- Always inspect the source code of scripts downloaded from the internet.
- Validate their integrity by checking commit tags or GitHub issues.
- Test on a Staging Environment:
- Before deploying scripts on production servers, test them in a safe environment.
- Regular Updates:
- Keep Proxmox VE and the Helper Scripts up to date to ensure compatibility and security.
- Backup Frequently:
- Use the Proxmox Host Backup Script to safeguard configurations.
- Maintain offsite backups for additional redundancy.
Should You Use Proxmox Helper Scripts?
Absolutely, Proxmox Helper Scripts provide a powerful and efficient way to automate routine tasks for various users and use cases:
- Homelab Enthusiast: Automates LXC container deployment, saving hours of manual setup.
- Enterprise IT Admin: Reduces downtime by scheduling Proxmox backups with the Host Backup Script.
- Small Business Owner: Saves storage space and optimizes system performance with the Kernel Cleanup Script.
However, while these scripts offer great flexibility, they require careful implementation, ongoing maintenance, and technical expertise for optimal performance.
A Better Alternative: Managed Services
If you’re looking to streamline your operations without the need for constant oversight and management, consider leaving the heavy lifting to us. Our managed private cloud services take care of everything—from automation to security and scalability—so you can focus on growing your business while we keep your Proxmox environment running smoothly.
Contact us today and let us handle the complexities of your Proxmox Virtual Environment.
Explore HorizonIQ
Bare Metal
LEARN MORE
Stay Connected
About Author