Month: September 2020

INAP Executive Spotlight: Jackie Coats, Senior Vice President, Human Resources
 In the INAP Executive Spotlight series, we interview senior leaders across the organization, hearing candid reflections about their careers, what they love about their work and big lessons learned along the way.
In the INAP Executive Spotlight series, we interview senior leaders across the organization, hearing candid reflections about their careers, what they love about their work and big lessons learned along the way.
Next in the series is Jackie Coats, Senior Vice President, Human Resources. In this role, she puts her passion for helping employees and leaders unlock their potential and accomplish goals to good use.
In our conversation, Coats discussed what drew her to this role at INAP, how she’s working with the other senior leaders to build a strong company culture and much more. Jackie brings her enthusiasm to the forefront of everything she does. Read on to learn more.
The interview has been lightly edited for clarity and length.
You joined INAP in May as the Senior Vice President of Human Resources. What excites you most about this new role?
The people at INAP are what attracted me to this role. I’d been consulting on my own and wasn’t in the market for going back to a regular full-time gig. I had the opportunity to come on as a contractor for INAP earlier this year. Every single person that I interacted with was smart, helpful and aligned with taking the business forward. The opportunity to be part of this team was a key driver in accepting the role. And as the company has now moved from public to private, I have the chance to build people functions that support the organization.
You came into this role during the COVID-19 pandemic. How does this impact company culture and what’s being done to connect with employees during this time?
The good thing is that our President and CEO Mike Sicoli genuinely cares about every single employee. It’s refreshing that he doesn’t delegate that to me alone as head of HR. All the senior leaders give a lot of thought to not only the productivity aspect of these times, as it’s important to keep a business running, but the emotional and personal impact that employees have undergone as a result of being remote. We’ve increased support tools and we’ve done surveys to check in with individual employees to take the pulse of the organization. We’ve connected leaders and given them tips on how to stay in sync with their teams. We’ve encouraged video one-on-ones in team meetings and all hands, etc. It’s something we definitely won’t stop beyond the pandemic. Knowing how our employees are feeling is important.
With all the social unrest going on in the world, diversity and inclusion is really important. Can you tell us about the steps INAP is taking in those areas?
We finalized the selection of a diversity, equity and inclusion consultant partner, and they have an amazing approach and lots of tools and partnerships that will help guide us. We’ll be doing work as a senior team, both together and individually, which I think is vital. We’ll also be doing an assessment of the organization to really get a baseline of where we stand. This consultant partner will help us identify areas where we need to focus.
It’s obvious from looking at the organization that we need to support the growth and professional development of our women and people of color, because as you go up in the organization, there’s fewer and fewer people in those categories. We’ll be working on development activities and support for those individuals. We’ll take a hard look at our policies and practices to consider how we promote, hire and transfer.
What changes have you see related to diversity and inclusion over your career? What do you still want to see?
What I have learned over the years is that grassroots-type exercises really are more valuable than big, government-mandated exercises. I’ve seen a lot of success with mentoring programs where you identify individuals and what they’re trying to achieve from a development perspective, and you match them with a senior person who has that expertise. Both parties learn a tremendous amount.
The need to hire quickly is generally what drives the hesitancy to take the time to find a diverse palate of candidates. As an organization and as a society, it’s absolutely critical that we develop our minority applicants and employees and go the extra mile to find people that bring diversity to the organization, because it’s critical for our success. There is a lot of data that shows businesses that are diverse are more productive and more successful.
You’ve worked in HR for other tech companies prior to joining INAP. What do you like best about being in the industry?
I’m a big believer that when you have pride in your organization, and in the products and services offered, employees are loyal and engaged. For me, technology touches absolutely everything. The fact that we’re powering and supporting businesses that are making our economy go brings a great sense of pride. And learning that some of our customers are in the gaming industry, I can connect that to having a kid who does all that stuff, so I love that.
How you go about setting goals for your team?
You need to have an overall vision for where you want your department or function to go. I talk a lot to my team about what we’re trying to achieve and what success would look like. We’re looking to add value to the organization, not just from an administrative or transactional standpoint. Our goal is to become consultative to the business leaders and help leaders and managers make excellent people decisions, support the growth of their individuals, improve the productivity of their teams, break down communication barriers across departments, recognize high performers and key contributors. That’s the big picture in what we’re trying to do.
Did you take any detours to get to where you are today?
I have a fashion merchandising degree and started in retail as a manager right out of the gate after graduating from college. Right away, I gravitated towards leadership and management. I realized that I had good transferrable skills, like hiring, coaching and training. I ended up taking a personnel training coordinator job at Lowe’s Home Centers, which tied the retail in with the HR function, and immediately saw a huge path of opportunity for me.
Of all the qualities you possess, which ones have the greatest influence on your success?
Enthusiasm. I bring a lot of positivity and enthusiasm for things that I believe in. My function should enable success, not get in the way. I have a quick ability to identify things that are getting in the way for people, and if they’re open to hearing it, I’m pretty good at helping them adjust their style to help them grow.
What are some of the biggest lessons you’ve learned in your career?
It’s important to surround yourself with people who possess talent and skills that you don’t have. I’ve learned to appreciate that you don’t have to have it all. You have to know what you need and you have to be able to find people to build a team with complementary skills. Bringing those complementary skills out in each of them has really helped me find success, for me and my teams.
Is there anything you would do differently now if you were just starting out?
I would’ve spent more time learning about data and metrics, and how to utilize them. Most business rely on data to help inform decisions and the people function is no different. Productivity, employee satisfaction and demographics are all KPIs that leaders need to know. Knowing the KPIs for your business helps to eliminate subjective decision making.
Explore HorizonIQ
Bare Metal
LEARN MORE
Stay Connected



About Author


IT Professionals Day 2020: 5 Reasons to Thank Your IT Team
Today is IT Professionals Day. This annual day of recognition was first celebrated in 2015 as a way to thank the people who keep the wheels of IT turning. And while we advocate thanking your IT team regularly, this year in particular our IT teams have taken on a lion’s share of work in helping many companies go remote, protecting us from ongoing cyberthreats and accelerating digital transformation initiatives. Preparing networks for remote work on a moment’s notice and ensuring applications remain resilient and performant is no easy task, but thanks to IT pros’ skills and agility, businesses have been able to continue on, many without missing a beat. In addition to their essential functions throughout the COVID-19 pandemic, below we’ve assembled five reasons to thank you IT team.
1. IT infrastructure managers go above and beyond around the clock.
On average, IT pros are interrupted 6.24 times a month during their personal hours with issues related to server and/or cloud infrastructure.
2. IT professionals are on the front lines of enterprise cybersecurity.
Daily, IT professionals are presented with 26.08 server and cloud-related alerts daily on average. This includes monitoring triggers, patches, updates, vulnerabilities and other issues.
3. Our IT teams are always there for us when things go wrong.
54% of pros say that they are only contacted by their coworkers when things go wrong, and 58% worry that senior leaders only view their function as “keeping the lights on.” But we too often fail to see all they to do help companies grow . . .
4. IT teams are key in helping our companies grow and innovate.
IT pros are hungry to move beyond routine activities and do the work that makes a greater impact for all of us. 47% want to spend more time on designing and implementing new solutions, and 59% of tech pros are frustrated by time spent on monitoring and OS maintenance. A whopping 83% say their departments should be viewed as centers for innovation.
5. IT pros continually educate themselves to keep pace with this ever-evolving field.
As such, 53.7% of IT pros say they feel like they’ve held 2-5 different roles since starting their careers in IT. In order to meet shifting demands, 37% of pros participate in training to learn new skills monthly, while 11% do so weekly.
Data derived from INAP’s annual State of IT Infrastructure Management report. The survey was conducted among 500 IT senior leaders and infrastructure managers in the United States and Canada.
Drop your IT team a note to let them know you appreciate their hard work and dedication. Or make a quick video to say, “thanks.” In the video below, INAP leadership thank our 100-plus essential data center workers. The terrific performance from these IT pros has enabled our thousands of global customers to successfully operate their businesses through a period of immense challenge.
Explore HorizonIQ
Bare Metal
LEARN MORE
Stay Connected


About Author

Choosing a Colocation Provider: Criteria and Questions to Find the Best Fit
Whether you are new to colocation or have been colocating for years, it is exciting and stressful to choose your next provider. A colocation provider is not just another vendor in your business solution, but rather a strategic partner for your business’ critical infrastructure needs. The right colocation providers can take your data center footprint and network to the next level, while the wrong provider can prevent you from reaching your full potential, and worse yet, negatively impact application availability and performance
To make the best-fit choice for your company, you’ll have to know your needs and goals and be able properly evaluate potential partners. Unsure of where to start? Read on for considerations and questions to get you on the right track.
Outline Criteria for Your Colocation Provider Search
When choosing a colocation provider, it is important to reflect on your needs prior to starting your search. Be sure to include the following considerations in your decision making:
Strategic Goals
Am I looking for a strategic colocation partner to help me power, connect and cool equipment for my critical business process/revenue generator, project in development or anything in between? This is important to understanding the next decision point.
Uptime
Uptime is always important in your colocation decision. Is this a test system I don’t really care about, or a revenue generator that will lose revenue during downtime? With any revenue generating system it is important to determine your downtime costs per second, minute, hour, day and so on. This is where your strategic colocation partnership is so important.
Is your colocation facility ready to provide you with unmatched uptime, support and advice to help you succeed? Have they even asked about your availability requirements? What are the provider’s SLAs and will they help you recoup financially in case of an outage caused by your colocation partner?
Growth Potential
Can your colocation partner accommodate your planned or unplanned growth in a timely manner? Nothing is worse than deploying a new application not expecting huge growth and realizing your colocation partner cannot accommodate your growth needs. This is what some call a “good problem to have,” but it’s still a problem. If you’re not able to quickly access more power, cooling and space, you can find yourself with a very dissatisfied consumer on the other end.
Know Your Market
Market/location is very important. Pricing could be great for power and cooling, but you may find yourself in a market with subpar interconnectivity, lack of diversity in connectivity providers or third parties and vendors in your vertical. Now your savings in cooling and power disappear with complicated connectivity solutions.
Geographic market locations are also very important to your user base. Low latency connectivity from your end user to your product is one of the best ways to deliver a good application experience. Thus, choosing a colocation provider that can offer you not just power, cooling and space and low latency and great connectivity options is huge plus.
Flexibility in Colo Design
Flexibility in terms of colocation design for your specific solution is very important. Your solution may require caged environments with multiple security measures including cameras, bio-metric locks, privacy screening, slab-to-slap cage walls, toppers and a plethora of other power/cooling and cabling options to meet your exact needs. This is where the right colocation partner matters.
Security Requirements
Security that meets your requirements is a decision point which should be at the top of your list. Is your colocation partner PCI and SOC2 compliant? What other compliances will you need your partner to meet? What certifications does your colocation partner maintain on a regular basis?
Cloud Options & Spend Portability
Some of your application stack is likely already in the cloud or would benefit from running in a cloud, on bare metal or in a fully managed private cloud. Does your colocation provider also offer bare metal, cloud and connectivity to cloud providers? And if you choose to shift to one of these solutions from your current colocation solution, does your provider offer a spend portability program? The ability to cost-effectively pivot to a different solution to best meet shifting infrastructure needs is invaluable.
Ask the Right Questions to Evaluate Potential Colocation Providers
Now that you’ve thought more about your needs, you can more easily assess colocation providers to find one that meets your specific criteria. Based on the decision points discussed above, let’s talk through specific questions that should be considered when evaluating a potential colocation partnership.
- What design is the colocation partner using for their power, cooling and space?
- N+1, N+1 with concurrent maintainability, N+2?
- What design is right for your solution?
- Is the colocation partner keeping mechanical equipment on the datacenter floor or away from the floor?I have some stories about this one, but that’s for another blog.
- How much uptime protection do you need? (Keeping in mind that all those pluses carry additional costs.)
- What is your market/location?
- Where is your customer geographically?
- What markets does your colocation partner cover?
- What power does your equipment require?
- What amount of power do you need per cabinet? This will depend on your equipment, so knowing ahead of time what you will put in your cabinet is important. You may want to populate a cabinet with networking gear which doesn’t require much power, so the maximum you will need is 2KW to 10KW. Or you may use many blade chassis with huge power requirements and 20KW to 30KW per cab. If your colocation partner cannot deliver high-density power to your cabinets, now you are expanding your colocation footprint sideways rather than vertically and not utilizing all your available rack space.
- What connectivity providers are available at the colocation space?
- What internet service providers (ISPs) are available in the data center’s meet me room?
- Does your colocation partner offer you a redundant IP blend?
- Is your colocation partner able to directly connect you to public clouds?
- Does your colocation partner also offer native bare metal or cloud services?
- What security measures are taken by your colocation partner to make sure that only you will gain access to your cabinets and services?
- Does your colocation partner offer you a comfortable, quiet place to focus, meet and get work done while at the datacenter?
What Sets INAP Colocation Apart?
INAP is not a cookie-cutter colocation partner. We’re extremely flexible with colocation design, effectively meeting the requirements of our customers no matter how simple or complex. And with INAP Interchange, our spend portability program, you can get the solution flexibility that you need after you deploy your initial solution. This allows you access to INAP Colo, Bare Metal and Cloud solutions to best meet your needs throughout INAP’s 47 Tier-3 data centers, including our flagship facilities in well-connected markets, along with 90 POPs around world.
INAP’s ability to deliver a level of service with N+1 and Concurrent Maintainability for power and cooling provides you with peace of mind that even during maintenance, your critical infrastructure is backed by redundant systems. Paired with state of the art, zoned fire suppression systems with VESDA (Very Early Smoke Detector Apparatus), you can rest assured that your infrastructure is in good hands. Additionally, high-density power is INAP’s specialty, with efficiency that meets LEED Platinum levels. And you’ll find our security systems meet PCI and SOC2 compliance.
Finally, what really sets INAP apart (other than what’s been covered above) is that all INAP facilities are staffed with tenured data center engineers and management staff ready to work directly with customers to help them succeed.
Explore HorizonIQ
Bare Metal
LEARN MORE
Stay Connected



About Author


Container technology and its ability to run software when moving from one environment to another has helped it grow in popularity over virtual machines, due to its lighter weight and use of fewer resources. Kubernetes is one of these container technologies that, when paired with an optimal deployment model, has the capability to automate application orchestration, scaling and management across computing environments.
In this piece, we will explore the process of deploying Kubernetes on bare metal servers.
What is Kubernetes?
Kubernetes is a portable, extensible platform for managing containerized workloads and services. It is an increasingly popular tool for moving workloads efficiently across platforms with less overhead than traditional virtual machines (VMs).
Kubernetes’s capability to automate application orchestration, scaling and management makes it a very attractive lightweight platform for deploying workloads at large scale. It has been gaining momentum as a form of building cloud-like environments for web-scale type of applications, especially on bare metal servers.
Why Deploy Kubernetes on Bare Metal?
Kubernetes can be deployed as a service offered by cloud provider or on top of a VM layer or on dedicated bare metal servers—either on-premises or in a hosted environment. Each model has its advantages and drawbacks in terms of speed of availability, complexity, management overhead, cost and operational involvement.
Bare metal offers the operational flexibility and scalability inherent in a cloud model in addition to on-demand capacity management. Bare metal servers allow for optimized configuration with better performance, efficient resource usage and predictable improved cost.
Setting Up Kubernetes on a Bare Metal Server: A Step-By-Step Process
Designing a High Availability Kubernetes Cluster on Bare Metal
For this exercise, we’ll deploy Kubernetes on a cluster of two control nodes and two worker nodes with a standalone HAProxy load balancer (LB) in front of the control nodes. Each node is a bare metal server. Three control nodes are typically recommended for a Kubernetes cluster allowing control nodes to form quorum and agree on cluster state, but in this exercise, we’ll use two nodes to demonstrate the high availability setup. We will use the following configuration for this exercise:
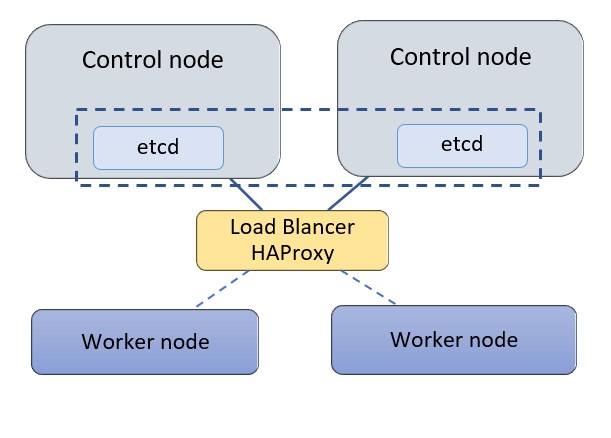
- Kubernetes 1.18.6 is being used on bare-metal machines with Ubuntu 18.04.
- The control nodes are used for control and management of the cluster, and they run cluster-wide components such as apiserver, controller-manager, scheduler and etcd. Etcd is a distributed key-value store for the critical data of a distributed system. Within Kubernetes etcd is used as the backend for service discovery and stores the cluster’s state and configuration. Etcd can be deployed on its own standalone nodes but for this exercise we will keep etcd within the control nodes.
- A standalone node is used for HAProxy to load balance traffic to the control nodes and support control plan redundancy.
- The servers use a private network (or vlan) to communicate within the cluster. In our case the network is 172.31.113.0/26
Jump to Step
Step 1: Configuring HAProxy as a Load Balancer
Step 2: Install Docker and Related Packages on All Kubernetes Nodes
Step 3: Prepare Kubernetes on All Nodes
Step 4: Install the Key-Value Store “Etcd” on the First Control Node and Bring Up the Cluster
Step 5: Add a Second Control Node (master2) to the Cluster
Step 6: Add the Worker Nodes
Step 1: Configuring HAProxy as a Load Balancer
In this step wewill configure HAProxy as a load balancer on a standalone server. This node could be a bare metal server or a cloud instance. To keep the deployment steps generic and easy to follow we will define the IP addresses of the nodes as environment variables on all the server nodes.
#create a file with the
list of IP addresses in the cluster
cat > kubeiprc <<EOF
export KBLB_ADDR=172.31.113.50
export CTRL1_ADDR=172.31.113.38
export CTRL2_ADDR=172.31.113.40
export WORKER1_ADDR=172.31.113.45
export WORKER2_ADDR=172.31.113.46
EOF
#add the IP addresses of the nodes as environment variables
chmod +x kubeiprc
source kubeiprc
Install the haproxy package:
apt-get update && apt-get upgrade && apt-get install -y haproxy
Update the HAproxy config file “/etc/haproxyhaproxy.cfg” as follows:
##backup the current file
mv /etc/haproxy/haproxy.cfg{,.back}
## Edit the file
cat > /etc/haproxy/haproxy.cfg << EOF
global
user haproxy
group haproxy
defaults
mode http
log global
retries 2
timeout connect 3000ms
timeout server 5000ms
timeout client 5000ms
frontend kubernetes
bind $KBLB_ADDR:6443
option tcplog
mode tcp
default_backend kubernetes-master-nodes
backend kubernetes-master-nodes
mode tcp
balance roundrobin
option tcp-check
server k8s-master-0 $CTRL1_ADDR:6443 check fall 3 rise 2
server k8s-master-1 $CTRL2_ADDR:6443 check fall 3 rise 2
EOF
To allow for failover, the HAProxy load balancer needs the ability to bind to an IP address that is nonlocal, meaning an address not assigned to a device on the local system. For that add the following configuration line to the sysctl.conf file:
cat >> /etc/sysctl.conf <<EOF
net.ipv4.ip_nonlocal_bind = 1
EOF
Update the system parameters and start or restart HAProxy:
sysctl -p
systemctl start haproxy
systemctl restart haproxy
Check that the HAProxy is working:
nc -v $KBLB_ADDR 6443

Step 2: Install Docker and Related Packages on All Kubernetes Nodes
Docker is used with Kubernetes as a container runtime to access images and execute applications within
containers. We start by installing Docker on each node.
First, define the environment variables for the nodes IP addresses as described in step 1:
cat > kubeiprc <<EOF
export KBLB_ADDR=172.31.113.50
export CTRL1_ADDR=172.31.113.38
export CTRL2_ADDR=172.31.113.40
export WORKER1_ADDR=172.31.113.45
export WORKER2_ADDR=172.31.113.42
EOF
#add the IP addresses of the nodes as environment variables
chmod +x kubeiprc
source kubeiprc
Update the apt package index and install packages to allow apt to use a repository over HTTPS:
apt-get update
apt-get -y install \
apt-transport-https \
ca-certificates \
curl \
gnupg2 \
software-properties-common
Add Docker’s official GPG key:
curl –fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add –

Add docker to APT repository:
add-apt-repository \
“deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable”
Install Docker CE:
apt-get update && apt-get install docker-ce
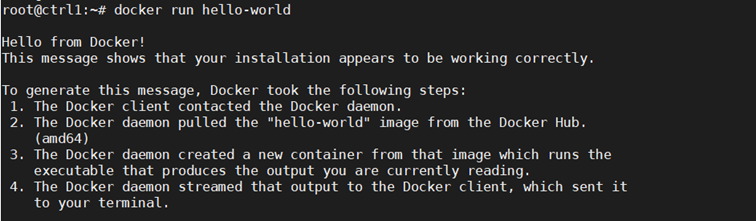
Next confirm Docker is running:

Step 3: Prepare Kubernetes on All Nodes, Both Control and Worker Ones
Install the Kubernetes components on the node. This step applies to both control and worker nodes.
Install kubelet, kubeadm, kubectl packages from the Kubernetes repository. Kubelet is the component that runs on all the machines in the cluster and is needed to start pods and containers. Kubeadm is the program that bootstraps the cluster. Kubectl is the command line utility to issue commands to the cluster.
Add the Google repository key to ensure software authenticity:
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add –

Add the Google repository to the default set:
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
Update and install the main packages:
apt-get update && apt-get install -y kubelet kubeadm kubectl
To ensure the version of these packages matches the Kubernetes control plan to be installed and avoid unexpected behavior, we need to hold back packages and prevent them from being automatically updated:
apt-mark hold kubelet kubeadm kubectl
After the package install, disable swap, as Kubernetes is not designed to use SWAP memory:
swapoff -a
sed –i ‘/ swap / s/^/#/’ /etc/fstab
Verify kubeadm utility is installed:
kubeadm version

Change the settings such that both docker and kubelet use systemd as the “cgroup” driver. Create the file /etc/docker/daemon.json:
Repeat Steps 2 and 3 above for all Kubernetes nodes, both control and worker nodes.
Step 4: Install the Key-Value Store “Etcd” on the First Control Node and Bring Up the Cluster
It is now time to bring up the cluster, starting with the first control node at this step. On the first Control node, create a configuration file called kubeadm-config.yaml:
cd /root
cat > kubeadm-config.yaml << EOF
apiVersion: kubeadm.k8s.io/v1beta1
kind: ClusterConfiguration
kubernetesVersion: stable
apiServer:
certSANs:
– “$KBLB_ADDR”
controlPlaneEndpoint: “$KBLB_ADDR:6443”
etcd:
local:
endpoints:
– https://$CTRL1_ADDR:2379
– https://$CTRL2_ADDR:2379
caFile: /etc/kubernetes/pki/etcd/ca.crt
certFile: /etc/kubernetes/pki/apiserver-etcd-client.crt
keyFile: /etc/kubernetes/pki/apiserver-etcd-client.key
EOF
Initialize the Kubernetes control plane:
sudo kubeadm init –config=kubeadm-config.yaml –upload-certs
If all configuration goes well, a message similar to the one below is displayed.
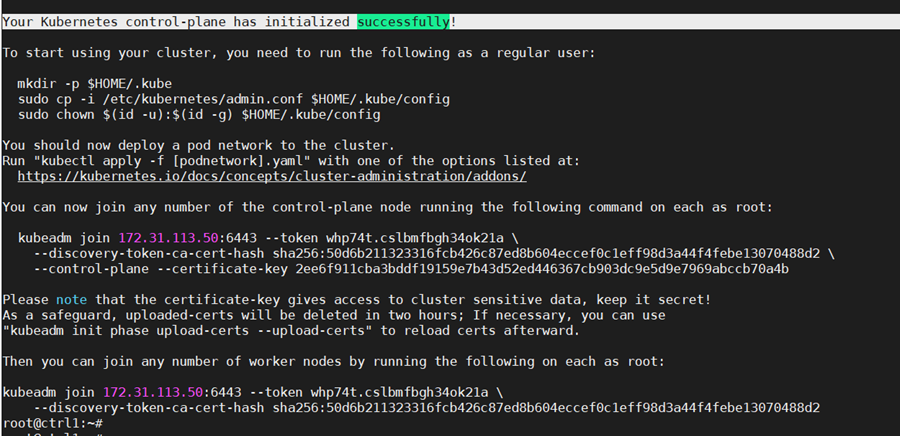
Kubeadm commands are displayed for adding a control-plane node or worker nodes to the cluster. Save the last part of the output in a file as it would be needed later for adding nodes.
Please note that the certificate-key gives access to cluster sensitive data. As a safeguard, uploaded-certs will be deleted in two hours.
On the configured control node, apply the Weave CNI (Container Network Interface) network plugin. This plugin creates a virtual network that connects docker containers deployed across multiple hosts as if the containers are linked to a big switch. This allows containerized applications to easily communicate with each other.
kubectl –kubeconfig /etc/kubernetes/admin.conf apply -f \
“https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d ‘\n’)”
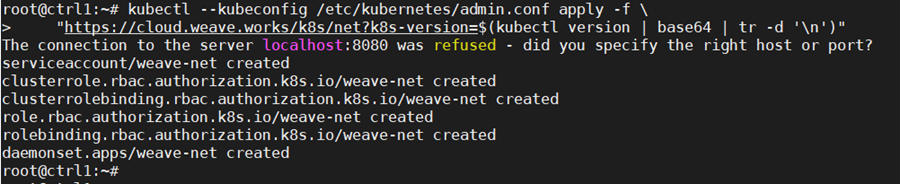
Check that the pods of system components are running:
kubectl –kubeconfig /etc/kubernetes/admin.conf get pod -n kube-system -w
kubectl –kubeconfig /etc/kubernetes/admin.conf get nodes
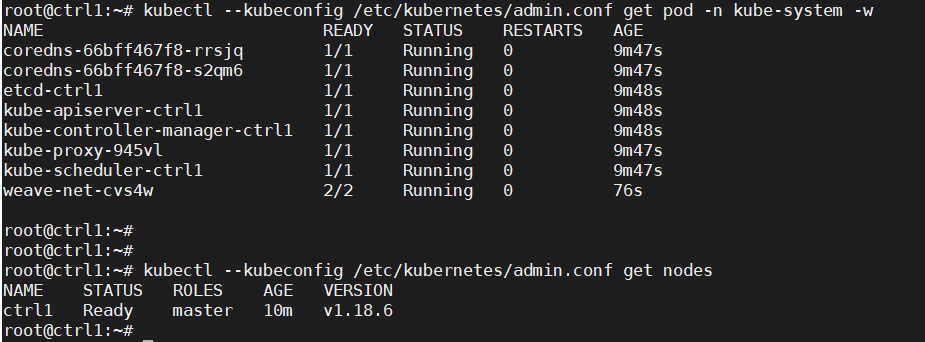
Step 5: Add a Second Control Node (master2) to the Cluster
As the fist control node is running, we can now add a second control node using the “kubeadm join” command. To join the master2 node to the cluster, use the join command shown in the output at the initialization of the cluster control plane on control node 1.
Add the new control node to the cluster. Make sure to copy the join command from your actual output in the first control node initialization instead of the output example below:
kubeadm join 172.31.113.50:6443 –token whp74t.cslbmfbgh34ok21a \
–discovery-token-ca-cert-hash
sha256:50d6b211323316fcb426c87ed8b604eccef0c1eff98d3a44f4febe13070488d2 \
–control-plane –certificate-key
2ee6f911cba3bddf19159e7b43d52ed446367cb903dc9e5d9e7969abccb70a4b
The output confirm that the new node has joined the cluster.
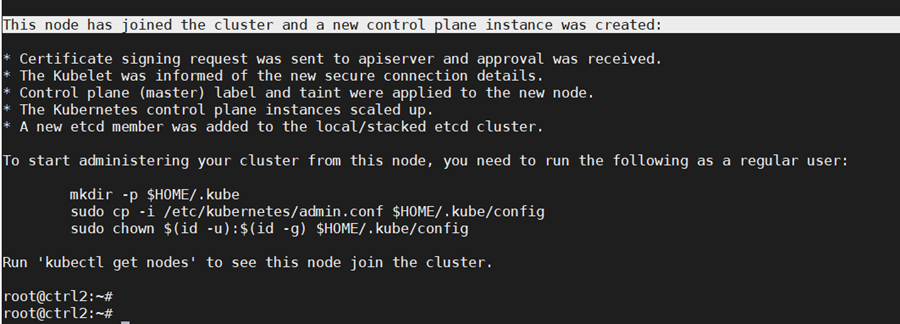
The “certificate-key” flag of the “kubeadm join“ command causes the control plane certificates to be downloaded from the cluster “kubeadm-certs” store to generate the key files locally. The security certificate expires and is deleted every two hours by default. In case of error, the certificate can be reloaded from the initial control node in the cluster with the command:
sudo kubeadm init phase upload-certs –upload-certs

Once the certificates are reloaded, they get updated and the “kubeadm join” needs to be modified to use the right “certificate-key” parameter.
Check that nodes and pods on all control nodes are okay:
kubectl —kubeconfig /etc/kubernetes/admin.conf get nodes
kubectl –kubeconfig /etc/kubernetes/admin.conf get pod -n kube-system -w
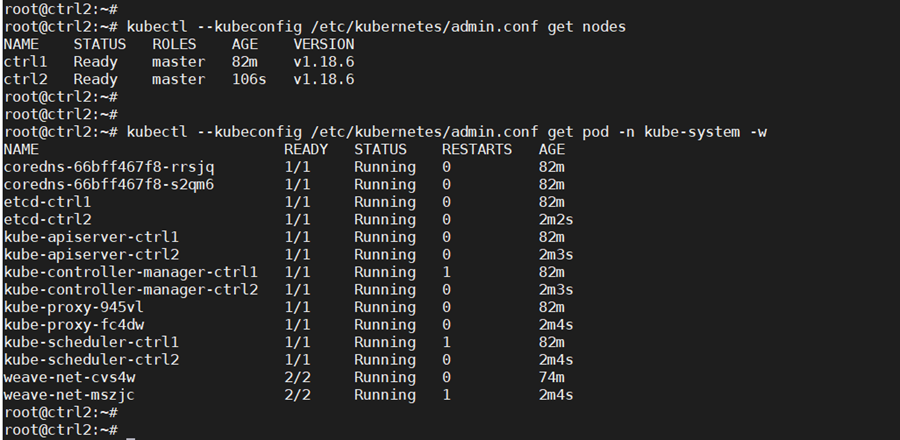
Step 6: Add the Worker Nodes
Now worker nodes can be added to the Kubernetes cluster.
To add worker nodes, run the “kubeadm join” command in the worker node as shown in the output at the initialization of the cluster control plane on the first control node (example below, use the appropriate command saved from the controller build):
kubeadm join 172.31.113.50:6443 –token whp74t.cslbmfbgh34ok21a \
–discovery-token-ca-cert-hash
sha256:50d6b211323316fcb426c87ed8b604eccef0c1eff98d3a44f4febe13070488d2
The output confirms the worker node is added.

Check the nodes that are in the cluster to confirm the addition:
kubectl –kubeconfig /etc/kubernetes/admin.conf get nodes

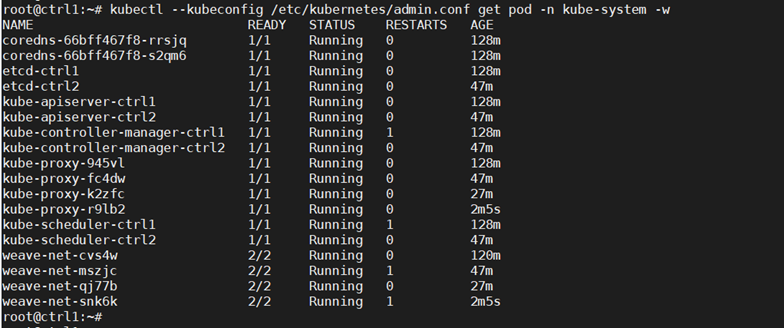
With this config we have deployed an HA Kubernetes cluster with two control nodes, two worker nodes and an HAProxy load balancer in front of the two control nodes.
The cluster deployed can be extended in a similar way as described above with more control nodes or additional worker nodes. Another HAProxy load balancer can be added for high availability.
Conclusion
The Kubernetes deployment demonstrated above used a cluster of bare metal servers. Using HorizonIQ Bare Metal servers, the same deployment can span multiple sites using additional networking plugins to achieve a highly available and scalable distributed environment. HorizonIQ Performance IP® can further optimize the inter-site connectivity by providing low latency for better overall performance of Kubernetes clusters.
Explore HorizonIQ
Bare Metal
LEARN MORE
Stay Connected


About Author