Month: January 2020

Survey: Monitoring and OS Maintenance are IT Pros Biggest Infrastructure Time Wasters
If time is considered a finite resource, IT pros are feeling a shortage.
For INAP’s second annual State of IT Infrastructure Management report, we asked IT professionals to list the routine infrastructure activities taking too much and too little of their time. Once again, monitoring topped the “too much time” list, while designing and implementing new solutions ranked No. 1 in the “not enough time” category.
Overall, 59 percent of IT pros are frustrated by the time spent on routine infrastructure activities and 84 percent agreed that they “could bring more value to their organization if they spent less time on routine tasks”—up 7 points from 2018.
The survey was conducted late last year among 500 IT senior leaders and infrastructure managers in the United States and Canada. The margin of error was +/- 5 percent.
Participants also shared how often their personal time is interrupted and how they would spend their time if they were given 16 hours back to use as they please.
Check out the results below and download a copy of the full report here.
How IT Pros Spend (And Don’t Spend) Their Time
Here’s the full list of routine infrastructure activities alongside IT’s assessment of whether each is getting the attention it deserves.
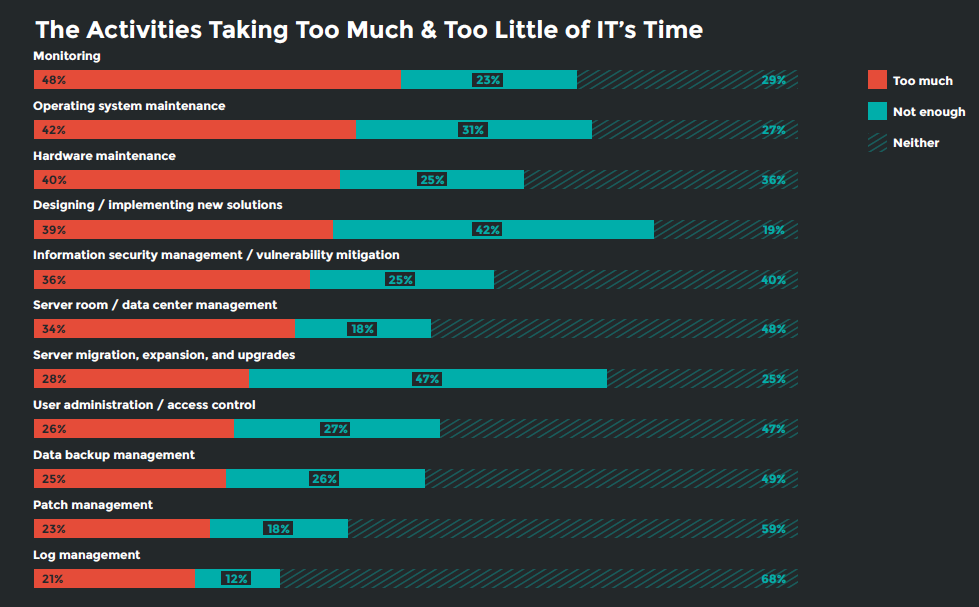
Only 23 percent of participants said they don’t spend enough time monitoring infrastructure, which is less than half the rate of those who consider this routine activity to be something that is eating into time that could be spent elsewhere (48 percent).
Operating system and hardware maintenance came in second and third, at 42 percent and 40 percent, respectively.
Nearly half (47 percent) of IT pros want to spend more time on designing and implementing new solutions, compared to 28 percent who already spend too much time.
IT pros remain polarized, as they were in the 2018 report, as to whether the amount of time spent securing their infrastructure is hitting the mark, with 39 percent saying it’s too much and 42 percent saying it’s not enough. Information security management/vulnerability migration is also the activity where the highest percentage of IT pros went one way or another on the issue, as only 19 percent fell into the “neither” category.
Senior leaders were far more likely to say they spend too much time on security compared to non-senior infrastructure managers—30 percent vs. 13 percent. They were also more likely to say they don’t focus enough on OS maintenance—20 percent vs 6 percent of non-leaders.
How IT Pros Would Like to Spend Their Time
Survey respondents say their personal time is disrupted by work responsibilities related to server and/or cloud infrastructure an average of 6.24 times per month—up slightly from 5.9 times in 2018’s report.
With so much time—on and off the clock—being dedicated to upkeep and maintenance, we once again asked, “What would you do if we gave you 16 hours back in your week?”
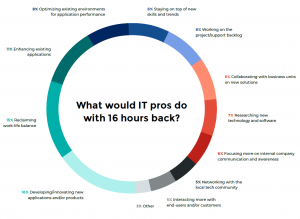
Application related answers make up three of the top four activities this year, with “enhancing existing applications” and “optimizing existing environments for application performance” coming in third and fourth, respectively. Reclaiming work-life balance fell to second, after claiming the top spot in 2018.
In the first annual State of IT Infrastructure Management report, IT pros noted that their departments are the key driver of their organization’s digital transformation initiatives, but they are spending too much time on routine tasks, focusing on functions that are “just keeping the lights on.” This sentiment continued in 2019. The list of activities noted in the chart above can be considered the opportunity costs of these routine tasks.
Have you read checked out our second annual State of IT Infrastructure Management report yet?
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected



About Author


Editor’s note: This article was originally published Dec. 4, 2019 on Adweek.com.
Latency—the delay that occurs in communication over a network—remains the enemy of Ad Tech, and by extension, the enemy of publishers and agencies relying on increasingly sophisticated tools to drive revenue and engage audiences.
With real-time bidding demanding sub-100 millisecond response times, advertisers are careful to avoid any process that could hinder their ability to win placements. Website page-load speeds, meanwhile, continue to be a critical metric for publishers, as adding tracking pixels, tags and content reload tech to page code can inadvertently increase latency, and as a result, website bounce rates.
If you think a few dozen milliseconds here or there won’t tank user experience, note that the human brain is capable of processing images far faster than we previously thought. An image seen for as little as 13 milliseconds can be identified later, according to neuroscientists at MIT. The drive for greater speed and better performance will march on because users will demand it.
At its core, latency reduction—like the mechanics of transporting people—is governed by both physics and available technology. Unless a hyperloop breaks ground soon, you will likely never make a trip from Los Angeles to Chicago in two hours. It’s a similar story for the data traversing internet fiber optic cables across the globe. Even with a high-speed connection, your internet traffic is still bound by pesky principles like the speed of light.
So how are Ad Tech companies solving for latency?
The two most straightforward answers are to simply move data centers closer to users and exchanges, or move the media itself closer via Content Delivery Networks. The shorter the distance, the lower the latency.
A third, lesser-known tactic involves the use of internet route optimization technologies (first developed and patented by my company) that operate much like Waze or any other real-time traffic app you might use to shave minutes off your commute. Deploying this tech can significantly reduce latency, which in the programmatic and digital ad space, can be directly correlated to upticks in revenue.
To understand how it works, let’s first consider how most internet traffic reaches your laptops, smart phones, and (sigh . . .) your refrigerators, doorbells and washing machines.
Unlike the average consumer, companies increasingly choose to blend their bandwidth with multiple internet service providers. In effect, this creates a giant, interconnected road map linking providers to networks across the globe. In other words, the cat video du jour has many paths it can take to reach a single pair of captivated eyeballs.
This blended internet service has two very real benefits for enterprises: It allows internet traffic to have a greater chance of always finding its way to users and sends traffic by the shortest route.
But there’s one very important catch: The shortest route isn’t always the fastest route.
In fact, the system routing internet traffic works less like real-time GPS routing and more like those unwieldy fold-out highway roadmaps that were a staple of many family road trips gone awry. They are an adequate tool for picking the shortest path from point A to point B, but can’t factor in traffic delays, lane closures, accidents or the likelihood of Dad deciding a dilapidated roadside motel in central Nebraska is the perfect place to stop for the day.
In much the same way, the default system guiding internet traffic selects a route based on the lowest number of network “hops” (think tollbooths or highway interchanges) as opposed to the route with lowest estimated latency. While the shortest path sometimes is the fastest, traffic is always changing. Congestion can throttle speeds. The cables carrying data can be accidentally severed, stopping traffic altogether. Human error can temporarily take down a data center or network routers. But unless someone intervenes, the system will keep sending your traffic through this path, to the detriment of your latency goals, and ultimately, your clients and end users.
Network route optimization technologies, conversely, manipulate this default system by probing every potential route data can take, diverting traffic away from routes with latency that kills user experience. While it is pretty easy for a company’s network engineering team to manually route traffic, it’s not practical at scale. The randomness and speed at which networks change mean even an always-on army of experts can’t beat an automation engine that makes millions of traffic optimizations per day.
Of course, latency is just one of many factors affecting the increasingly innovative Ad Tech space. For instance, services capable of intelligently delivering content users actually want to see is pretty important for all parties, too. And as an avid content consumer myself, I’m thankful more Ad Tech providers are turning their eyes toward the user experience.
But that’s all moot if industry leaders lose sight of the fact that milliseconds matter. And they matter a lot. Success in Ad Tech, as with any service powering the digital economy, is only as good as the data center technology and the network delivering the goods.
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected


About Author


Hindsight 2020: The IT Infrastructure Advancements that Caught Pros by Surprise
From the release of the original iPad in 2010 to the profound shift in how we consume media through video streaming, with 2019 marking the release of Apple TV+ and Disney+, the last decade yielded an abundance of technological developments that directly or indirectly impacted information technology pros. Change and advancement are inevitable, but some progress only feels inevitable in hindsight.
In the world of IT infrastructure and operations, some developments we may have seen coming, such as Microsoft’s release of Azure in 2010 after Amazon’s release of AWS in 2006, and others may have taken us by surprise, like the rise of blockchain.
As we welcome in 2020 and the start of a new decade, we decided to ask senior IT professionals and infrastructure managers to take a look back:
What is one advancement or change in IT infrastructure since 2010 you did not anticipate?
The question yielded a wide variety of answers, but cloud-related responses easily took the top spot. The graphic below shows the percentage breakdown of the 420 submitted responses by category.
Take a look at the breakdown and read on to learn more about the cloud feedback we received from participants, along with a sample of answers from the other top categories.
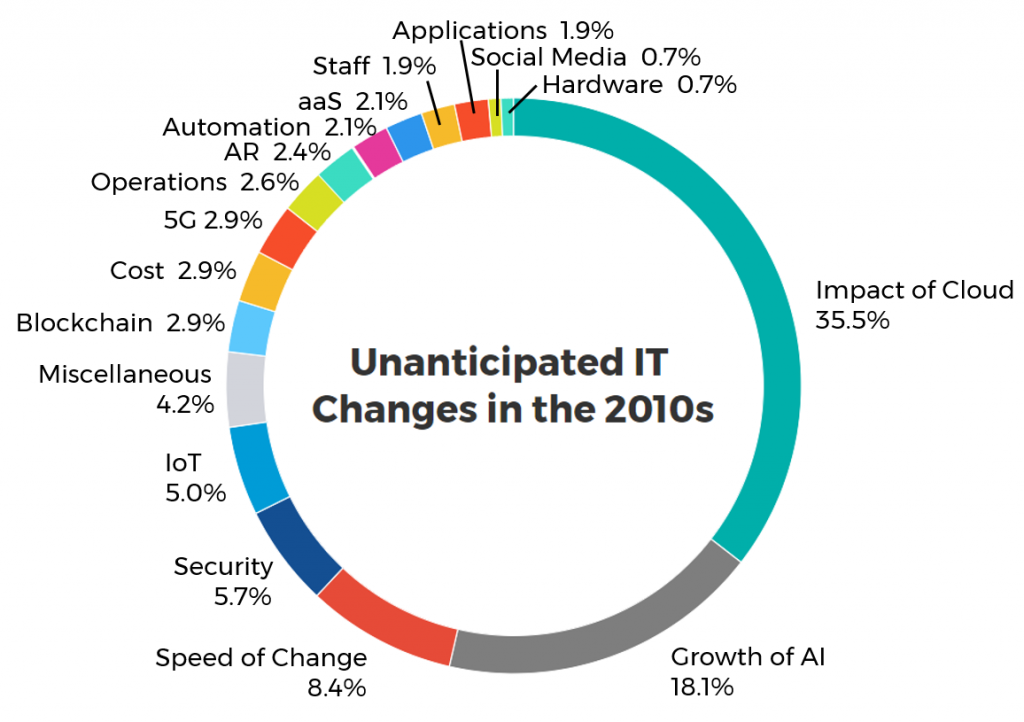
Everything Cloud
35.5%
While cloud infrastructure is undoubtedly here to stay, it’s prevalence didn’t seem quite as inevitable 10 years ago, according to many IT pros. Respondents expressed surprise at the wide-spread adoption of the cloud, noting specifically that it was surprising that it caught on outside of the tech industry.
- I did not think that use of the cloud would actually catch on. When it first debuted, no one thought it was a good idea because of the security risks that they thought it posed. Now it’s an industry standard.
- I did not expect the cloud to become so easily adopted in non-tech organizations. It took little encouragement from me to make this transition.
- Cloud use. I didn’t think companies would be migrating to the cloud at such a fast rate.
- The mass migration into cloud computing. I knew the technology was up and coming, but the way it was embraced was a surprise.
The popularity of public cloud took one participant by surprise.
- The idea of public hosting in the business world. I would have guessed most companies would have preferred private cloud in order to maintain a sense of control over their own data.
While the public cloud, like AWS and Azure, witnessed exponential growth, private clouds are projected to be a big part of the future of IT infrastructure. According to our second annual State of IT Infrastructure Management report, hosted private cloud is a leading solution for workloads being migrated off-premise, with 77 percent of applications currently hosted on-prem being moved to hosted private cloud.
Artificial Intelligence and Machine Learning
18.1%
AI and machine learning are next on the list. The rapid adoption of AI took many by surprise, and the overall impact this will have on the industry and the world is still unknown. In some cases, the technology may make the way we work more cost effective, and in others it will affect how we do our jobs, quite possibly making some functions obsolete.
- I did not expect to have AI be implemented so soon in the workplace. I thought that it would’ve taken a much longer time!
- That AI would develop so rapidly. It’s been around for so long but even in 2010, had not gained much traction. But now it’s just exploded.
- How integral AI would become to lowering costs/increasing revenue.
- I always imagined that someday technology was going to take over roles in IT infrastructure, but I thought that companies were going to still need human knowledge. I did not anticipate the extent of capabilities of AI and machine learning.
While we think the odds of AI heralding the end times is unlikely, one respondent seems to think we already have begun the struggle against AI sometime over the last decade:
We’ll just have to wait and see.
The Need for Increased Security
5.7%
With the rapid adoption of the cloud and other new infrastructures and technologies, we’ve also seen the scope of vulnerabilities widen. Cybersecurity is always at the top of mind for IT pros, many of whom noted the adoption of new authentication techniques over the last decade.
- I did not anticipate the rapid expansion of biometric authentication techniques.
- The increase of overall need of security in the IT department
Retinal and fingerprint scans might have been something you’d only see in a spy movie back in the 90s, but biometric and two factor authentication is commonly used today, from our smart phones to data center entrances and checkpoints.
Respondents also noted that, with certain functions in IT threatened by AI, machine learning and automation, cybersecurity would have been a good area to focus on had they known when they entered the field how important it would become.
- How important security is. If I had been smarter this is what I would have gone into.
Speed of Technological Changes
8.4%
Another top answer category had to do with the speed at which new technology and practices are adopted. Many pros find that keeping up is difficult, leading to shifting perspectives on the role IT pros play in their organizations. This rapid adoption of new technology can also lead to potential staffing issues as it becomes more of challenge to find qualified professionals.
- Since 2010, I didn’t anticipate how fast technology would develop, and how quick we would need to implement it.
- I did not anticipate that technology would move and grow so fast that we can’t find and keep trained people.
- It has matured and grown very quickly. There is always something new. Hard to keep up with it growing and changing.
For one respondent, though, some things aren’t moving fast enough.
- The slow conversion to fully fiber-based connectivity or completely wireless workstation connectivity. Can’t believe Cat5 and Cat6 cables still being run on new installs.
The Internet of Things (IoT)
5%
The rise of more reliable and faster network connectivity allowed the Internet of Things to take off in the last decade. The IT pros we interviewed never expected to see IoT adoption in general, much less in people’s everyday lives.
- IoT devices. No one saw it coming with the connectivity speed. Now it is a reality.
- IoT hype and to an extent implementation is happening on a relatively squeezed timescale.
- The overall hype of IoT. I never imagined people would care if their toaster or coffee maker could connect to their phone or anything else.
Miscellaneous Answers and a Fortunetelling Side Hustle
4.2%
With everything that can take place in the span of 10 years, it wasn’t a surprise that a number of answers didn’t fall cleanly into a category. A number of participants generally extolled the virtues of the changes over the last decade.
One IT pro noted that there wasn’t any point in anticipating change. Sometimes it’s best to just roll with what comes to you.
- I don’t worry about unanticipated changes because change is constant. My colleagues and I take the innovations that come our way and try to run with them.
And another respondent stated that nothing took him by surprise.
- I foresaw everything that has taken place. I am always ahead of the curve on these things and my company is consistently well prepared because of it.
A word of advice: Find this prognosticator of prognosticators for your company so you’ll be ahead of the curve throughout the 20s.
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected
About Author

Silicon Valley Data Center Market Overview
As the preeminent technology hub of the U.S., it should come as no surprise that the data center market in Silicon Valley is among the largest in the country, and it’s only growing. New space is slated to come online over the next few years, driven by (and in some ways dependent on) the technology sector. Other industries that drive demand in this market include mobility, IoT, financial technology and bioscience.
Santa Clara specifically houses the majority of data centers in this market and is appealing to providers and users for its relatively low electricity costs. And despite the premium on real estate in the region, as well as the fact that the region is prone to earthquakes, proximity to corporations and end users makes the Silicon Valley market a key location for many companies, driving continued growth.
Considering Silicon Valley for a colocation, network or cloud solution? There are several reasons why we’re confident you’ll call INAP your future partner in this competitive market.
INAP’s Santa Clara Flagship Data Center
INAP has seven data centers and points of presence in Silicon Valley, and an additional three locations in the Bay Area and Sacramento. The Silicon Valley flagship facility is located in Santa Clara at 2151 Mission College Blvd. The 75,000 square-foot data center is designed with Tier 3 compliant attributes and offers 10 MW of utility power.
The flagship, as well as INAP’s other data center locations and POPs in this market, provide a backbone connection to Seattle, Chicago, Los Angeles and Dallas through our high-capacity private network. INAP’s Connectivity Solutions product suite provides high availability and scalable connectivity services across our global network, allowing customers to build the high-performance network their applications and users demand. Paired with Performance IP®, INAP’s patented route optimization software, customers in our Santa Clara flagship get the application availability and performance their customers demand.
Here are the average latency benchmarks on the backbone connection from Santa Clara:
- Seattle: 19.0 ms
- Chicago: 51.0 ms
- Los Angeles: 9.3 ms
- Dallas: 39.7 ms
Download the spec sheet on our Silicon Valley data centers and POPs here [PDF].
The flagship includes the following features:
- Power and Space: 24-inch raised floors, high-density configurations, including cages, cabinets and suites
- Facilities: Break rooms, meeting rooms, onsite engineers with remote hands, 24/7/365 NOC
- Energy Efficient Cooling: 1,200 tons of cooling capacity and N+1 with concurrent maintainability
- Security: Key card access with secondary biometric authentication, video surveillance with a minimum of 90 days video retention, 24/7/365 onsite personnel
- Network: Performance IP® mix (AT&T, Cogent, Silicon Valley Power (Dark Fiber), Zayo, CenturyLink, Level 3, XO Communications, Comcast) for patented traffic route optimization, geographic redundancy and Metro Connect fiber that enables highly available connectivity within the region via our ethernet rings
- Compliance: PCI DSS, HIPAA, SOC 2 Type II, LEED, Green Globes and ENERGY STAR, independent audits
Download the spec sheet on our Santa Clara Flagship data center here [PDF].
Gain Reliability, Connectivity and Speed with INAP Performance IP®
In a market that requires low latency and high availability for some of the world’s most trafficked applications and websites, INAP’s Performance IP® is a game changer. Our patented route optimization engine makes a daily average of 500 million optimizations per POP. It automatically puts your outbound traffic on the best-performing, lowest-latency route. Learn more about Performance IP® by checking out the video below or test out the solution for yourself by running a destination test from our flagship Santa Clara data center.
Spend Portability Appeals for Future-Proofing Infrastructure
Organizations need the ability to be agile as their needs change. With INAP Interchange, INAP Silicon Valley data center customers need not worry about getting locked into a long-term infrastructure solution that might not be the right fit years down the road.
Colocation, Bare Metal and Private Cloud solutions are eligible for Interchange. The program allows customers to exchange infrastructure environments a year (or later) into their contract so that they can focus on current-state IT needs while knowing they will be able to adapt for future-state realities. For example, should you choose a solution in a data center in the Silicon Valley, but find over time that you need to be closer to a user base in Phoenix, you can easily make the shift.
You can learn more about the INAP Interchange by downloading the FAQ.
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected



About Author

Check This Overlooked Setting to Troubleshoot ‘Strange’ Microsoft SQL Server Performance Issues
As a SQL DBA or a system admin of highly transactional, performance demanding SQL databases, you may often find yourself perplexed by “strange” performance issues reported by your user base. By strange, I mean any issue where you are out of ideas, having exhausted standard troubleshooting tactics and when spending money on all-flash storage is just not in the budget.
Working under pressure from customers or clients to resolve performance issues is not easy, especially when C-Level, sales and end users are breathing down your neck to solve the problem immediately. Contrary to popular belief from many end users, we all know that these types of issues are not resolved with a magic button or the flip of a switch.
But what if there was a solution that came close?
Let’s review the typical troubleshooting process, and an often-overlooked setting that may just be your new “magic button” for resolving unusual SQL server performance issues.
Resolving SQL Server Performance Issues: The Typical Process
Personally, I find troubleshooting SQL related performance issues very interesting. In my previous consulting gigs, I participated in many white boarding sessions and troubleshooting engagements as a highly paid last-resort option for many clients. When I dug into their troubleshooting process, I found a familiar set of events happening inside an IT department specific to SQL Server performance issues.
Here are the typical steps:
- Review monitoring tools for CPU, RAM, IO, Blocks and so on
- Start a SQL Profiler to collect possible offending queries and get a live view of the slowness
- Check underlying storage for latency per IO, and possible bottle necks
- Check if anyone else is running any performance intensive processes during production hours
- Find possible offending queries and stop them from executing
- DBAs check their SQL indexes and other settings
When nothing is found from the above process, the finger pointing starts. “It’s the query.” “No, it’s the index.” “It’s the storage.” “Nope. It’s the settings in your SQL server.” And so it goes.
Sound familiar?
An Often-Forgotten Setting to Improve SQL Server Performance
Based on the typical troubleshooting process, IT either implements a solution to prevent identical issues from coming back or hope to fix the issue by adding all flash and other expensive resources. These solutions have their place and are all equally important to consider.
There is, however, an often-forgotten setting that you should check first—the block allocation size of your NTFS partition in the Microsoft Windows Server.
The block allocation setting of the NTFS partition is set at formatting time, which happens very early in the process and is often performed by a sysadmin building the VM or bare metal server well before Microsoft SQL is installed. In my experience, this setting is left as the default (4K) during the server build process and is never looked at again.
Why is 4K a bad setting? A Microsoft SQL page is 8KB in size. With a 4K block, you are creating two IO operations for every page request. This is a big deal. The Microsoft recommended block size for SQL server is 64K. This way, the page is collected in one IO operation.
In bench tests of highly transactional databases on 64K block allocation in the NTFS partition, I frequently observe improved database performance by as much as 50 percent or more. The more IO intensive your DB is, the more this setting helps. Assuming your SQL server’s drive layout is perfect, for many “strange performance” issues, this setting was the magic button. So, if you are experiencing unexplained performance issues, this simple formatting setting maybe just what you are looking for.
A word of caution: We don’t want to confuse this NTFS block allocation with your underlying storage blocks. This storage should be set to the manufacturer’s recommended block size. For example, as of recently, Nimble storage bock allocation at 8k provided best results with medium and large database sizes. This could change depending on the storage vendor and other factors, so be sure to check this with your storage vendor prior to creating LUNs for SQL servers.
How to Check the NTFS Block Allocation Setting
Here is a simple way to check what block allocation is being used by your Window Server NTFS partition:
Open the command prompt as administrator and run the following command replacing the C: drive with a drive letter of your database data files. Repeat this step for your drives containing the logs and TempDB files:
- fsutil fsinfo ntfsinfo c:
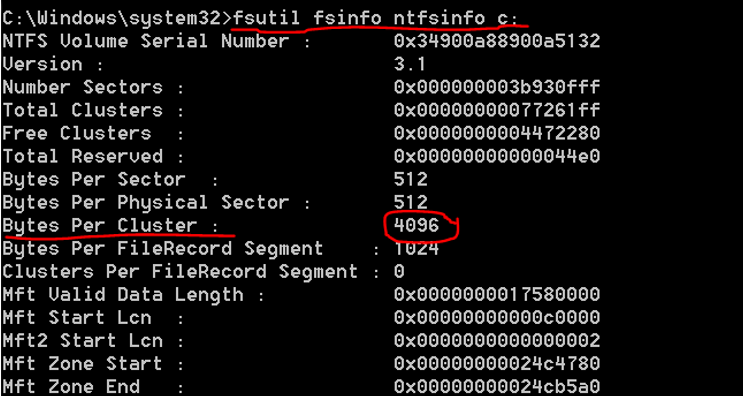
Look for the reading “Bytes Per Cluster.” If it’s set to 4096, that is the undesirable 4K setting.
The fix is easy but could be time consuming with large database sizes. If you have an AlwaysOn SQL cluster, this can be done with no downtime. If you don’t have an AlwaysOn MSSQL cluster, then a downtime window will be required. Or, perhaps it’s time to build an AlwaysOn SQL cluster and kill two birds with one stone.
To address the issue, you will want to re-format the disks containing SQL data with 64K blocks.
Concluding Thoughts
If your NTFS block setting is at 4K right now, moving the DB files to 64K formatted disks will immediately improve performance. Don’t wait to check into this one.
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected



About Author

Cloud Security Tips for Financial Services: 5 Key Takeaways from an Industry Expert
Today we are pleased to welcome guest blogger Tony Bradley, Senior Manager of Content Marketing for Alert Logic, INAP’s trusted managed security partner and expert in cloud security for financial services customers.
– Wendy Williams, Product Manager, INAP
Show me the money, and I’ll show you a cybercriminal ready to attack.
The sophistication of digital financial services and mobile banking have greatly expanded the attack surface criminals can exploit. While technology has given us the luxuries of quickly depositing a check via our mobile device or shopping online, it has also created ever evolving security challenges.
Planning your cloud security strategy? Below are five key takeaways for IT infrastructure pros in the financial services space:
1. Moving to the cloud changes the entire approach to security. A comprehensive view of your environment is critical, so choose a partner who can provide security monitoring of the environment, as well as network intrusion detection, vulnerability management and log management.
2. The level of expertise and the amount of people needed to maintain compliance using exclusively in-house services is cost prohibitive for all but the rarest of enterprises. The best options are to evaluate a trusted managed services partner or adopt technology that integrates services as part of the solution.
3. eCommerce has paved the way to unprecedented growth and revenue but opens doors to exponential compliance and threat risks. Using public cloud providers calls for 24/7 platform security. It is important to understand who has what security responsibility when utilizing cloud platforms and service providers. Furthermore, it pays to spend time evaluating whether or not your solution provider and partner have a deep understanding of your preferred platform. If they don’t, look elsewhere. This approach will ensure hard-to-detect web attacks such as SQL injection, path traversal and cross-site scripting risks are mitigated.
4. A solution may complement in-house capabilities, however, sometimes getting the right resources becomes a balancing act. As the hottest market today, security experts are scarce. In fact, according to (ISC)2, a non-profit IT security organization, there are an estimated 2.93 million cybersecurity positions open and unfilled around the world. The best advice is to develop a relationship with a service provider and a partner who can truly be an extension of your internal team and who has both the technology and resources to ensure constant surveillance, as well as the ability to stand up to any rigorous compliance audit.
5. We’ve only just witnessed the beginning of technologies touting AI capabilities. If you’re ready to adopt an AI-based solution for cybersecurity, ensure that it can draw on data sets of wildly different types, allowing the “bigger picture” to become clear from not only static configuration data and historic local logs but global threat landscapes and concurrent event streams, as well.
It’s more important than ever for businesses in the financial services industry to have the right tools and partners in place. Remember: Any solution you choose should be more than widgets and a slick UI. Too much is on the line. The road to holistic cloud security begins with proper implementation and infrastructure design, detailed, best practice configuration, and a plan for continuous monitoring and threat response. Chat with our partners at INAP today to get started.
 About the Author
About the Author
Tony Bradley is Senior Manager of Content Marketing for Alert Logic. Tony worked in the trenches as a network administrator and security consultant before shifting to the marketing and writing side of things. He is an 11-time Microsoft MVP in security and cloud and has been a CISSP-ISSAP since 2002. Tony has authored or co-authored a dozen books on IT and IT security topics, and is a prolific contributor to online media sites such as Forbes and DevOps.com.
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected


About Author


Network Redundancy vs. Network Diversity: What’s the Difference, and Do I Need Both?
Network redundancy is a duplicated infrastructure where additional or alternate instances of network devices and connections are installed to ensure an alternate path in case of a failure on the primary service. This is how you keep your business online and available should your main path of communication go down.
While redundancy is great, many times services are in the same data center, share the same fiber bundle, patch panel or equipment. In fact, hardware failures and fiber cuts are the leading causes of network outages today.
Being redundant may not protect you as well as planned.
What is Network Redundancy vs. Network Diversity?
A duplicate or alternate instance of your network doesn’t always protect you from the leading causes of network outages, and it can’t always protect you from less frequent, but more catastrophic incidents, like floods or fires. Sometimes construction work, human error and even squirrels can interrupt your network service. To protect against these scenarios, network diversity is the answer.
Network diversity takes redundancy one step further, duplicating your infrastructure on a geographically diverse path, in another data center or even in the cloud.
How do I Achieve Network Diversity Through Geographic Redundancy?
Diversity is key. Being geographically diverse protects you from weather events, construction and other single location incidents. If your redundant site is in a different state, or even in another country, your chances of two impacting events at the same time are significantly lessened. For even greater resiliency, you can move your redundancy or disaster recovery to the cloud via a Disaster Recovery as a Service solution.
Achieving Network Diversity via Multihomed BGP
You can achieve network diversity by being in geographically diverse data centers with the use of multihomed BGP. HorizonIQ offers the use of several BGP communities to ensure immediate failover of routing to your data center environment in case of a failure. Additionally, through HorizonIQ’s propriety technology, Performance IP®, your outbound traffic is automatically put on the best-performing route.
Achieving Network Diversity Through Interconnection
Another consideration is the connection from the data center to your central office. One can assume just because you have two different last mile providers for your redundancy that they use different paths. This usually is not the case; many fiber vaults and manholes are shared. This can result in both your primary and back up service being impaired when a backhoe unearths an 800-strand fiber. Ask the provider to share the circuit path to ensure your services are on diverse paths. HorizonIQ works to avoid these issues by offering high-capacity metro network rings in key markets. Metro Connect interconnects multiple data centers with diverse paths, allowing you to avoid single points of failure for your egress traffic.
Looking to migrate without overlap costs?
Migration shouldn’t drain your budget. With HorizonIQ’s 2 Months Free, you can move workloads, skip the overlap bills, and gain extra time to switch providers without double paying.Get 2 Months Free
Conclusion
Redundancy is key to maintain the demanding uptime of today’s business. In most cases this does the job, however, if your model is 100 percent uptime, it may be beneficial to start investing in a diverse infrastructure, as well.
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected
About Author
